12节点集群StarWind HyperConverged Appliance(HCA)可提供670万IOPS,由英特尔® Xeon® Platinum 8268处理器和英特尔® Optane™ SSD DC P4800X系列硬盘以及基于Supermicro SuperServers的Mellanox ConnectX-5 100GbE 网卡提供支持,所有这些都使用Mellanox LinkX®铜缆连接到Mellanox SN2700 Spectrum™交换机。

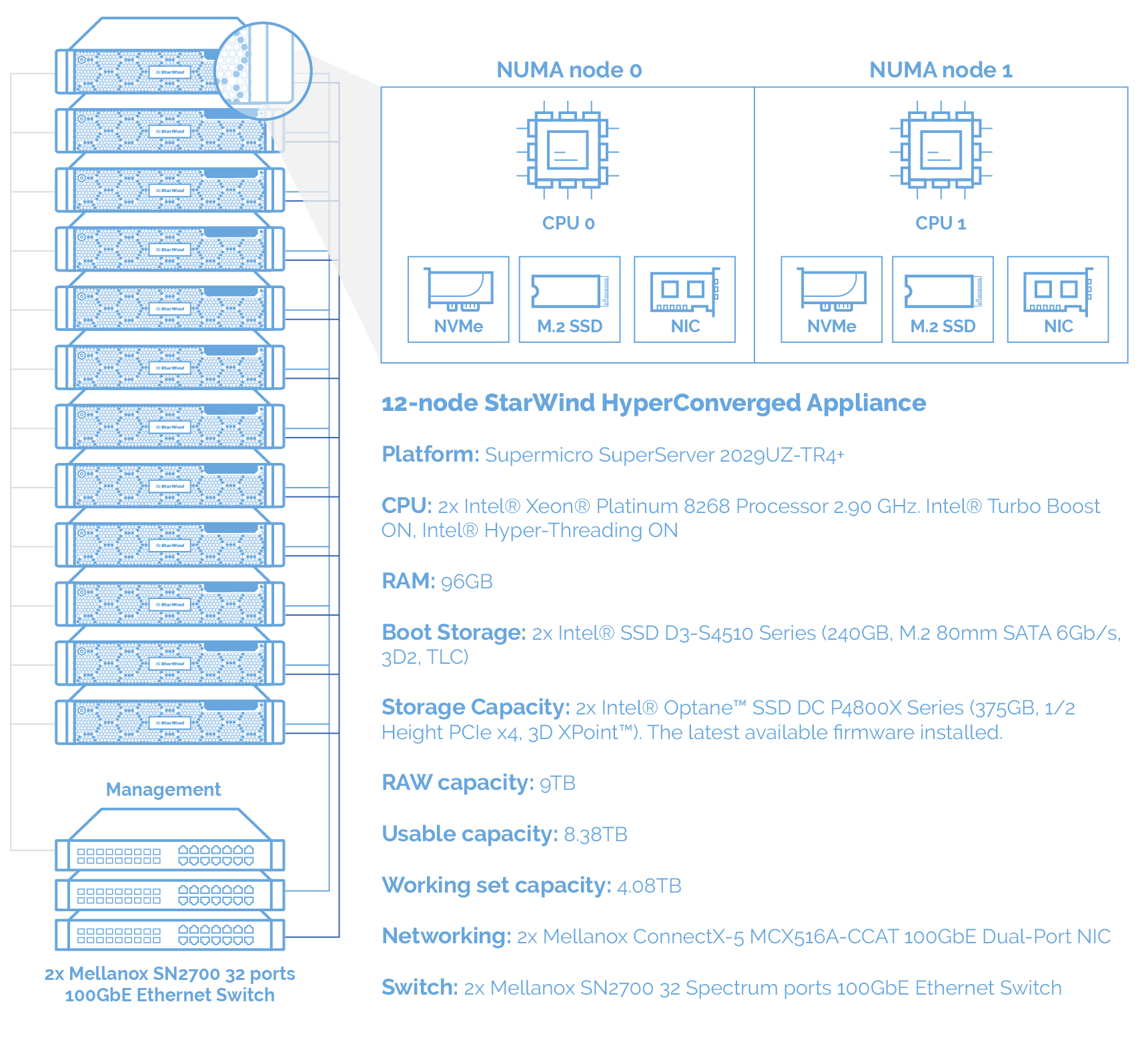 注意: 在每台服务器上,每个NUMA节点都有1个Intel®SSD D3-S4510、1个Intel®Optane™SSD DC P4800X系列和1个Mellanox ConnectX-5 100GbE双端口网卡。 这种配置能够从每个硬件中挤出最大性能。 这样的连接不是推荐而是严格的要求。 为了获得类似的性能,不需要调整NUMA节点配置,这意味着默认设置是可以的。
注意: 在每台服务器上,每个NUMA节点都有1个Intel®SSD D3-S4510、1个Intel®Optane™SSD DC P4800X系列和1个Mellanox ConnectX-5 100GbE双端口网卡。 这种配置能够从每个硬件中挤出最大性能。 这样的连接不是推荐而是严格的要求。 为了获得类似的性能,不需要调整NUMA节点配置,这意味着默认设置是可以的。
 驱动程序安装。 固件升级
驱动程序安装。 固件升级 StarWind iSCSI加速器(负载平衡器)。 我们将内置的Microsoft iSCSI Initiator与我们自己的用户模式iSCSI 启动器一起使用。 Microsoft iSCSI启动器是在“石器时代”开发的,当时服务器具有一个或两个插槽的CPU,每个插槽一个内核。 如今拥有更强大的服务器,启动器并没有发挥它应有的作用。
StarWind iSCSI加速器(负载平衡器)。 我们将内置的Microsoft iSCSI Initiator与我们自己的用户模式iSCSI 启动器一起使用。 Microsoft iSCSI启动器是在“石器时代”开发的,当时服务器具有一个或两个插槽的CPU,每个插槽一个内核。 如今拥有更强大的服务器,启动器并没有发挥它应有的作用。
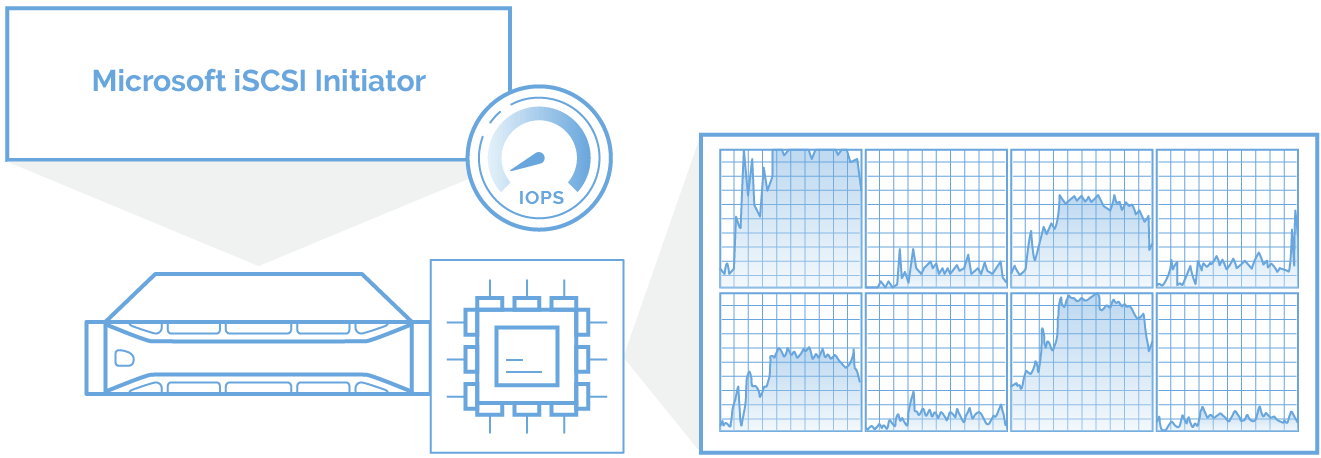 因此,我们开发了iSCSI加速器作为Microsoft iSCSI启动器和网络堆栈之间的筛选器驱动程序。 每次创建新的iSCSI会话时,都会将其分配给空闲的CPU内核。 因此,将统一使用所有CPU内核的性能,并且延迟接近零。 通过这种方式分配工作负载可确保智能计算资源的利用率:没有内核不堪重负,而其他内核则处于空闲状态。
因此,我们开发了iSCSI加速器作为Microsoft iSCSI启动器和网络堆栈之间的筛选器驱动程序。 每次创建新的iSCSI会话时,都会将其分配给空闲的CPU内核。 因此,将统一使用所有CPU内核的性能,并且延迟接近零。 通过这种方式分配工作负载可确保智能计算资源的利用率:没有内核不堪重负,而其他内核则处于空闲状态。
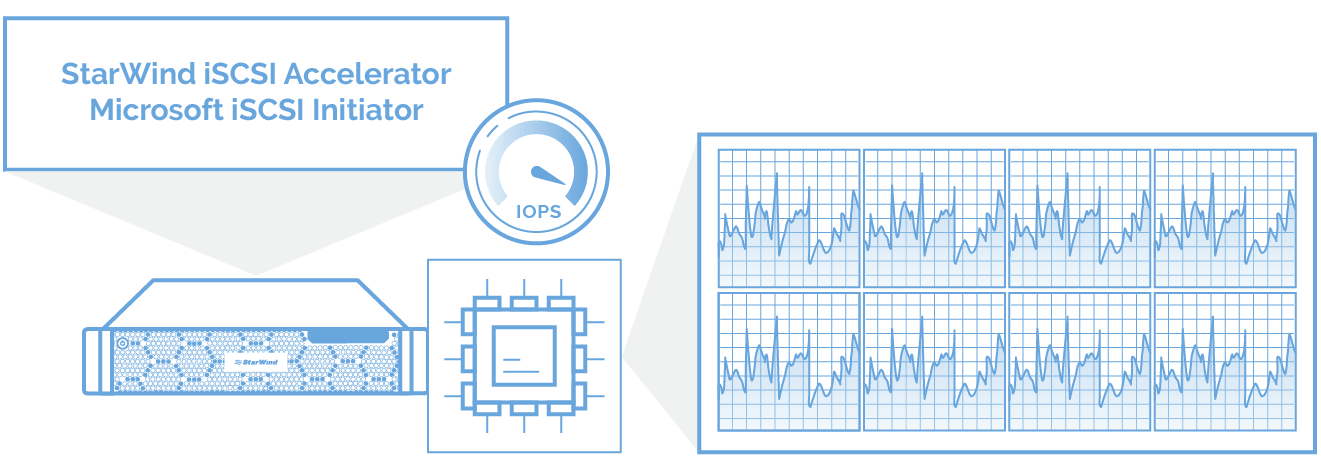 StarWind iSCSI Accelerator(负载均衡器) 安装在每个群集节点上,以平衡Hyper-V服务器中所有CPU内核之间的虚拟化工作负载。
StarWind iSCSI Accelerator(负载均衡器) 安装在每个群集节点上,以平衡Hyper-V服务器中所有CPU内核之间的虚拟化工作负载。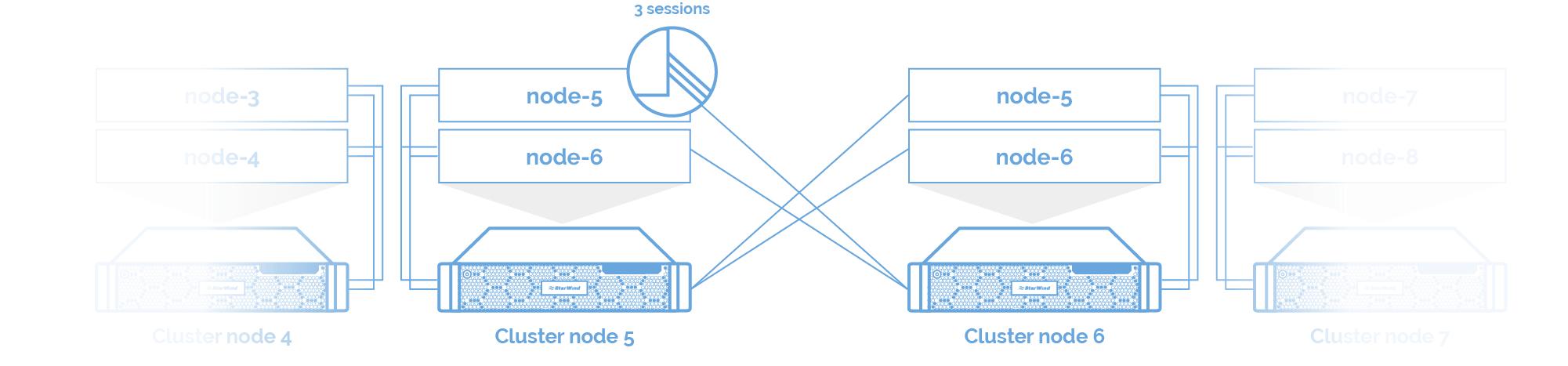 iSCSI/iSER (RDMA)模块 与StarWind HyperConverged Appliances一样,12节点HCI集群采用Mellanox网卡和交换机。在这项研究中,StarWind Virtual SAN利用iSER作为RDMA的主干链路,提供最大可能的性能。
iSCSI/iSER (RDMA)模块 与StarWind HyperConverged Appliances一样,12节点HCI集群采用Mellanox网卡和交换机。在这项研究中,StarWind Virtual SAN利用iSER作为RDMA的主干链路,提供最大可能的性能。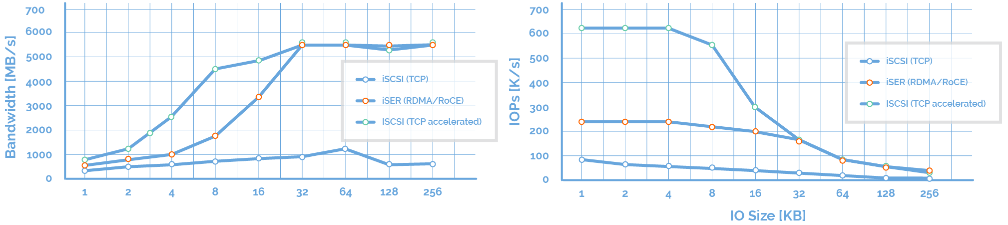 因此,通过RDMA、环回中的DMA和TCP连接的组合,加快了IO性能。
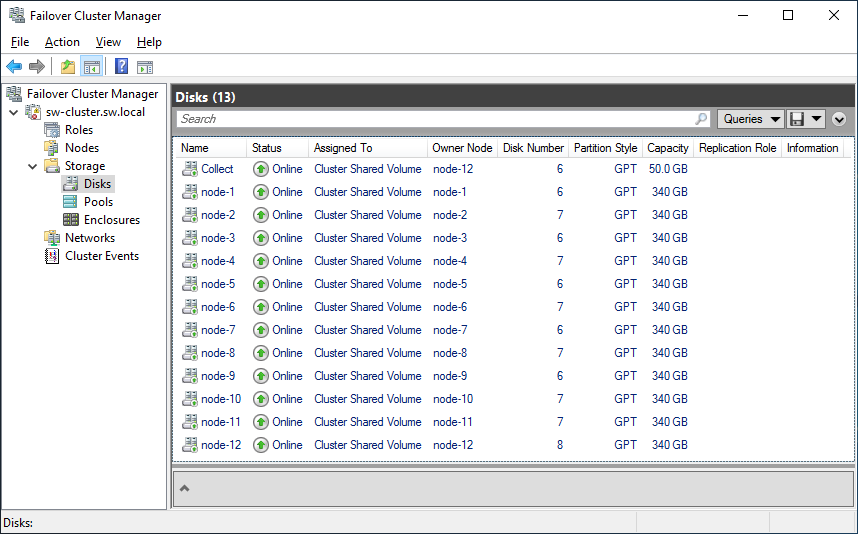
因此,通过RDMA、环回中的DMA和TCP连接的组合,加快了IO性能。 CSV。 对于12节点超融合群集,根据Microsoft的建议,在12个同步镜像的StarWind虚拟磁盘之上创建了12个群集共享卷。
CSV。 对于12节点超融合群集,根据Microsoft的建议,在12个同步镜像的StarWind虚拟磁盘之上创建了12个群集共享卷。
 Hyper-V虚拟机。 根据经验归纳,我们取12个虚拟机×每2个虚拟处理器=24个虚拟处理器,以使所有性能饱和。这就是12个服务器节点上总共144个Hyper-V Gen 2虚拟机。每个虚拟机运行Windows Server 2019标准版,并被分配了2 GiB的内存。
Hyper-V虚拟机。 根据经验归纳,我们取12个虚拟机×每2个虚拟处理器=24个虚拟处理器,以使所有性能饱和。这就是12个服务器节点上总共144个Hyper-V Gen 2虚拟机。每个虚拟机运行Windows Server 2019标准版,并被分配了2 GiB的内存。
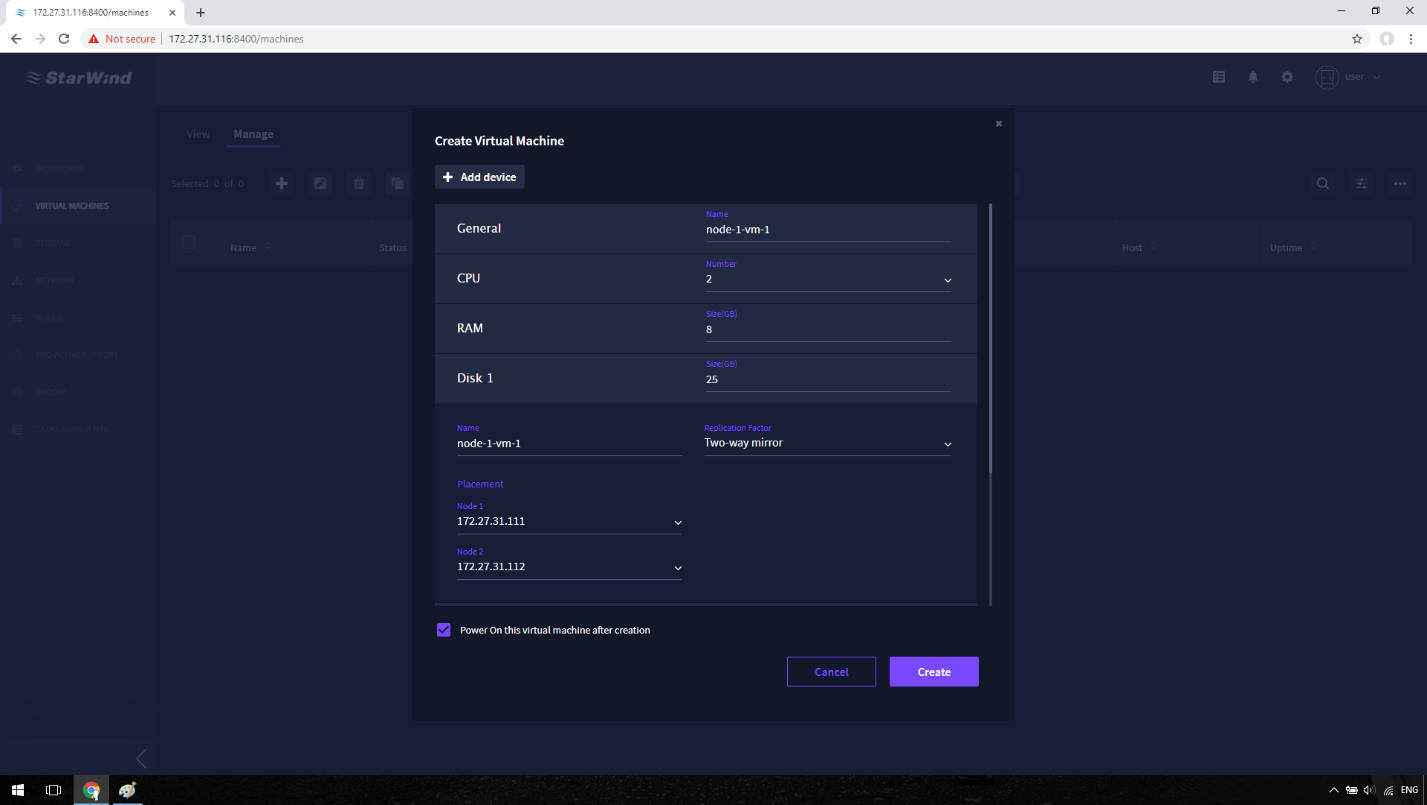 注意: 已禁用NUMA扩展,以确保虚拟机始终根据有关NUMA扩展的已知事实始终以最佳性能运行。
注意: 已禁用NUMA扩展,以确保虚拟机始终根据有关NUMA扩展的已知事实始终以最佳性能运行。
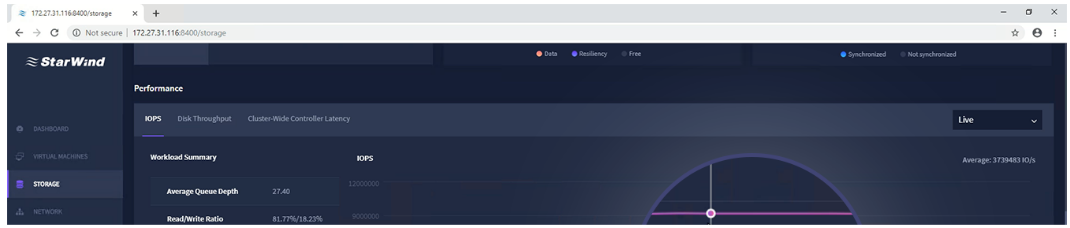
 例如,StarWin命令中心存储性能操作面板具有一个交互式图表,绘制了在 Windows 中 CSV 文件系统层测量的群集范围内的总 IOPS。DISKSPD 和 VM Fleet 的命令行输出中提供了更详细的报告。
例如,StarWin命令中心存储性能操作面板具有一个交互式图表,绘制了在 Windows 中 CSV 文件系统层测量的群集范围内的总 IOPS。DISKSPD 和 VM Fleet 的命令行输出中提供了更详细的报告。
 存储性能的另一面是延迟--一个IO需要多长时间才能完成。许多存储系统在重度排队下表现更好,这有助于最大化堆栈每一层的并行性和繁忙时间。但是有一个权衡:排队会增加延迟。例如,如果你能在亚毫秒级延迟的情况下做到100 IOPS,如果你能容忍更高的延迟,你可能也能达到200 IOPS。
存储性能的另一面是延迟--一个IO需要多长时间才能完成。许多存储系统在重度排队下表现更好,这有助于最大化堆栈每一层的并行性和繁忙时间。但是有一个权衡:排队会增加延迟。例如,如果你能在亚毫秒级延迟的情况下做到100 IOPS,如果你能容忍更高的延迟,你可能也能达到200 IOPS。
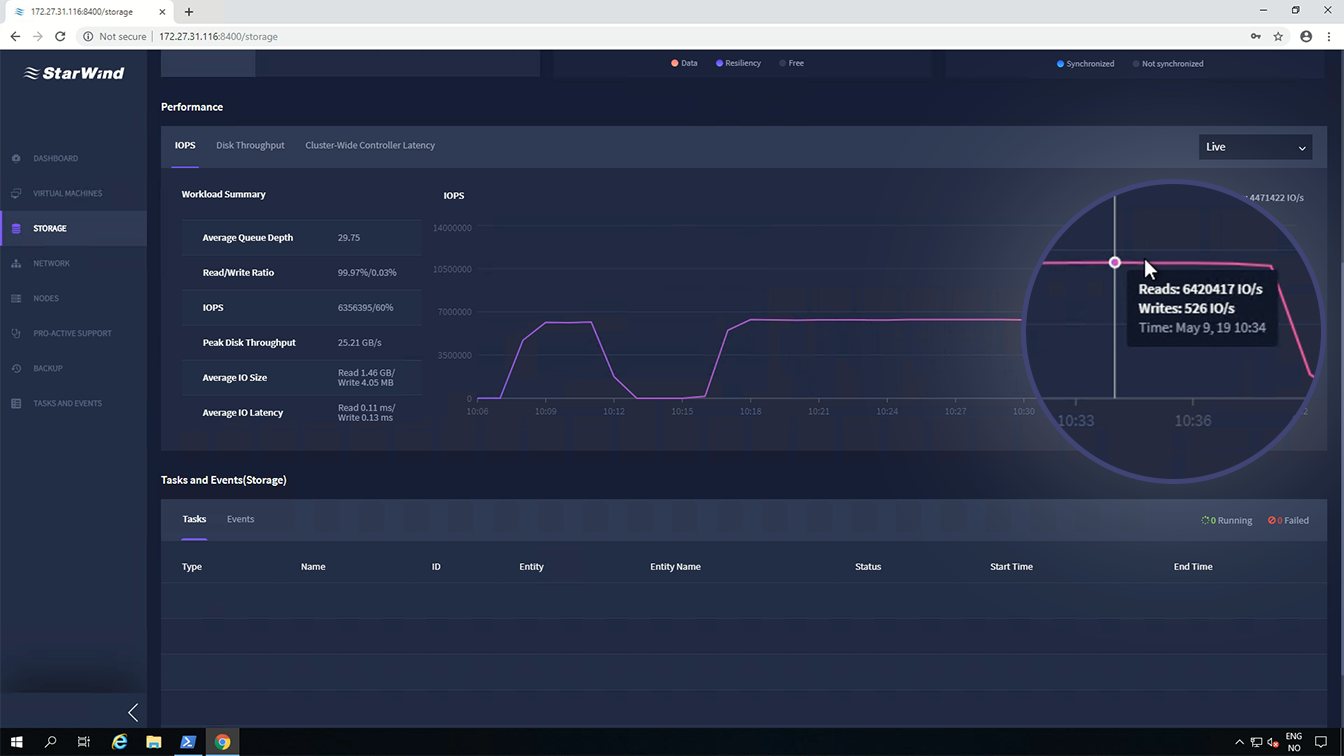 操作2: 4К random read/write 90/10 --> .\Start-Sweep.ps1 -b 4 -t 2 -o 32 -w 10 -p r -d 900
操作2: 4К random read/write 90/10 --> .\Start-Sweep.ps1 -b 4 -t 2 -o 32 -w 10 -p r -d 900